1. Introduction
-
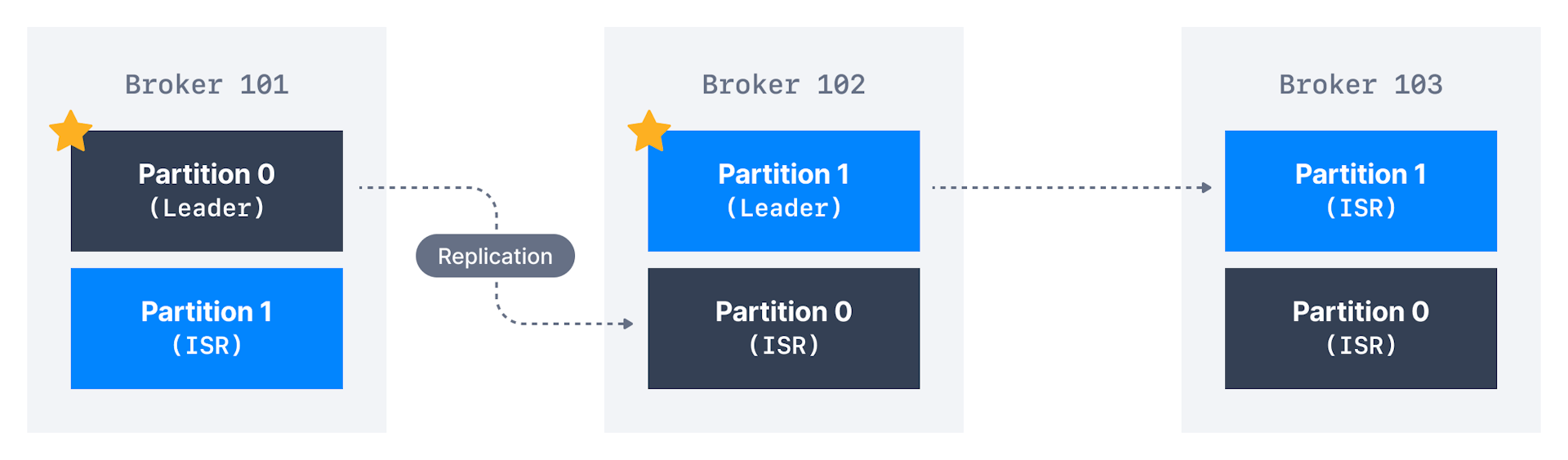
创建主题时,必须提供分区数partition count和复制因子replication factor;
-
此两选项影响系统的performance和durability
-
若分区数在主题生命周期topic lifecycle内增加,
将破坏Key的排序保证break key ordering guarantee; -
若复制因子在主题生命周期内,则会给集群带来更大压力,
可能因broker使用更多网络流量和额外空间而导致性能意外下降,请慎重;
-
最好第一次就获得正确的分区数和复制因子;
2. Choose Partition Number
|
|
|
|
3. Choose Replication Factor
|
|
|