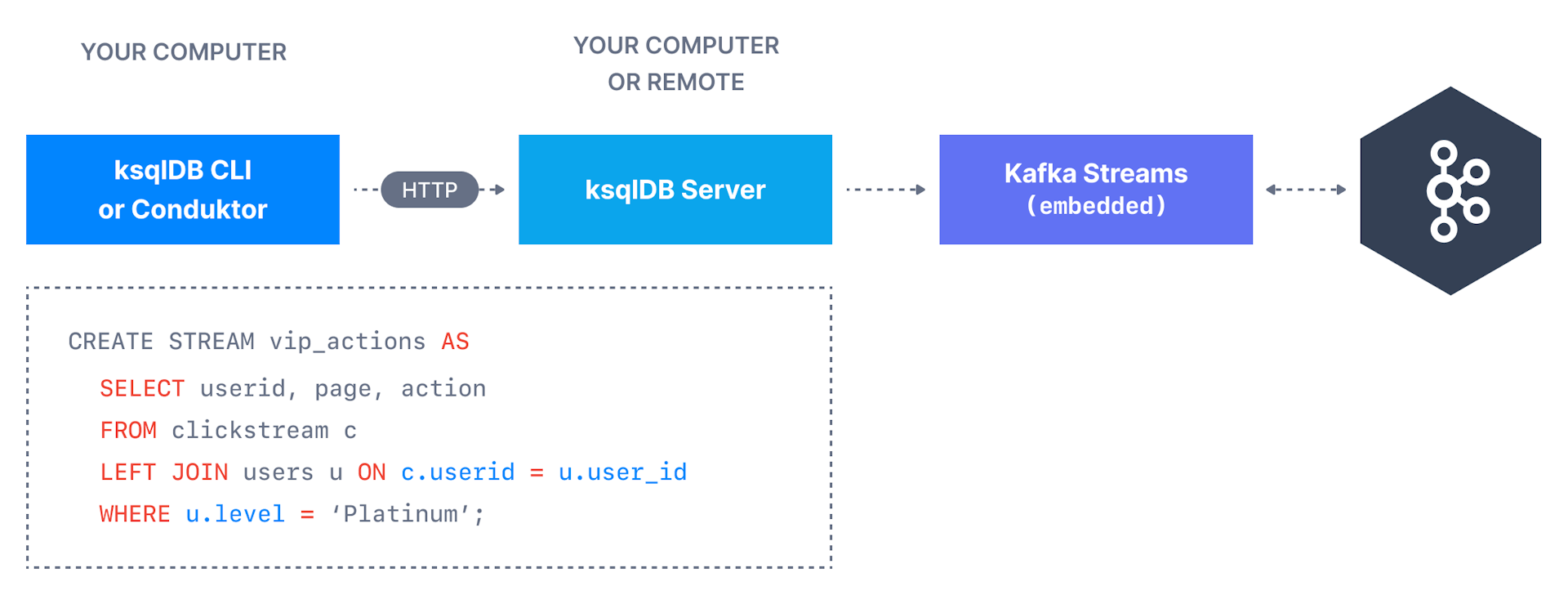
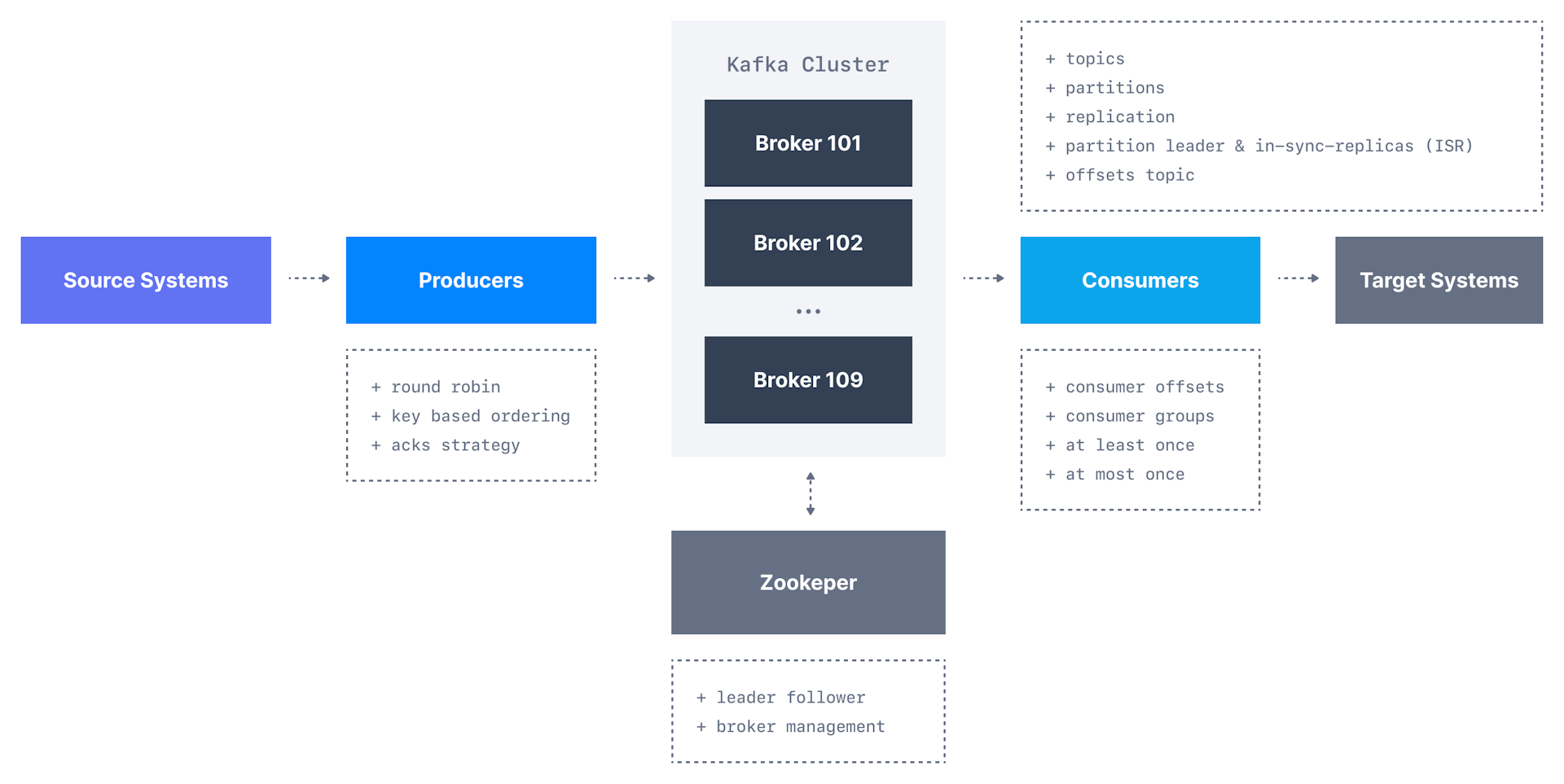
1. Integration
1.1. Integration Challenge
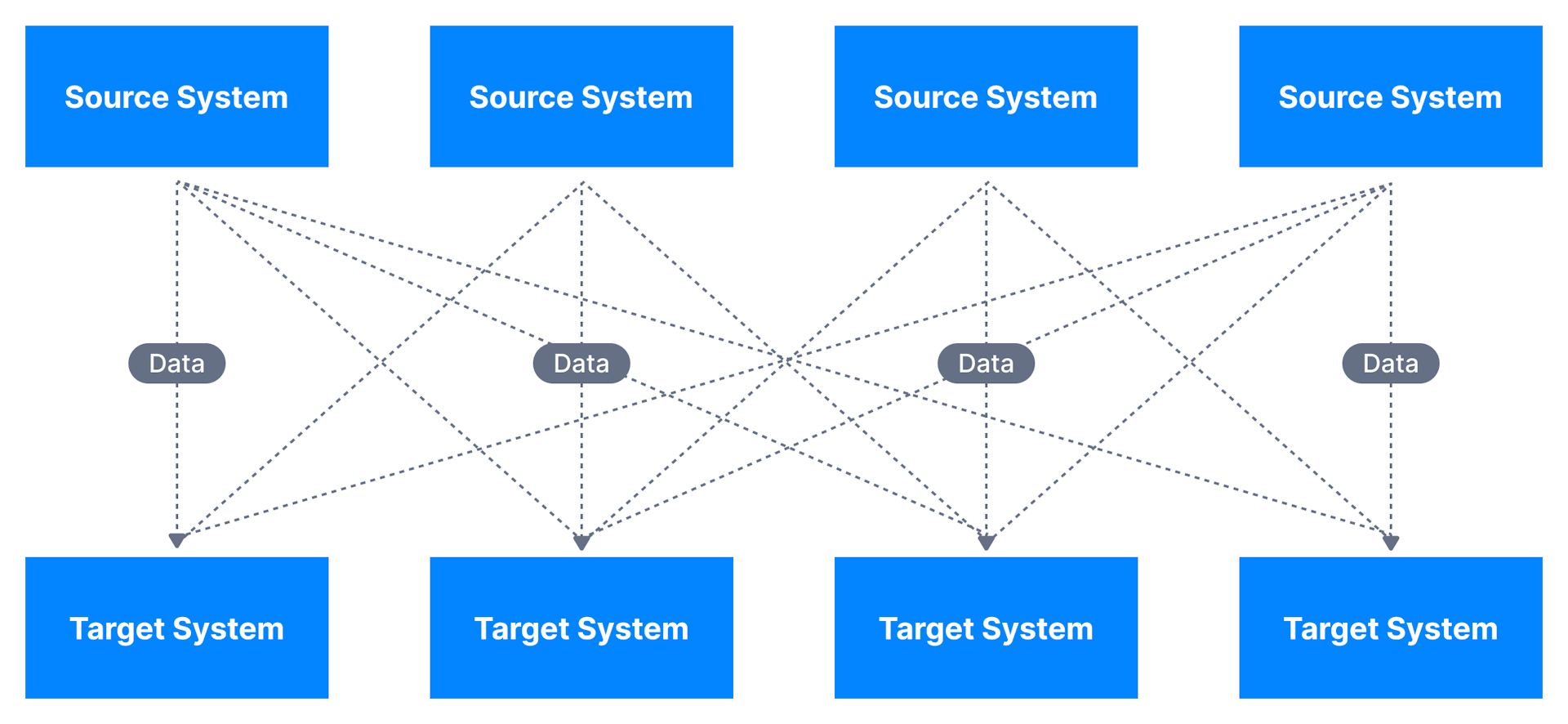
-
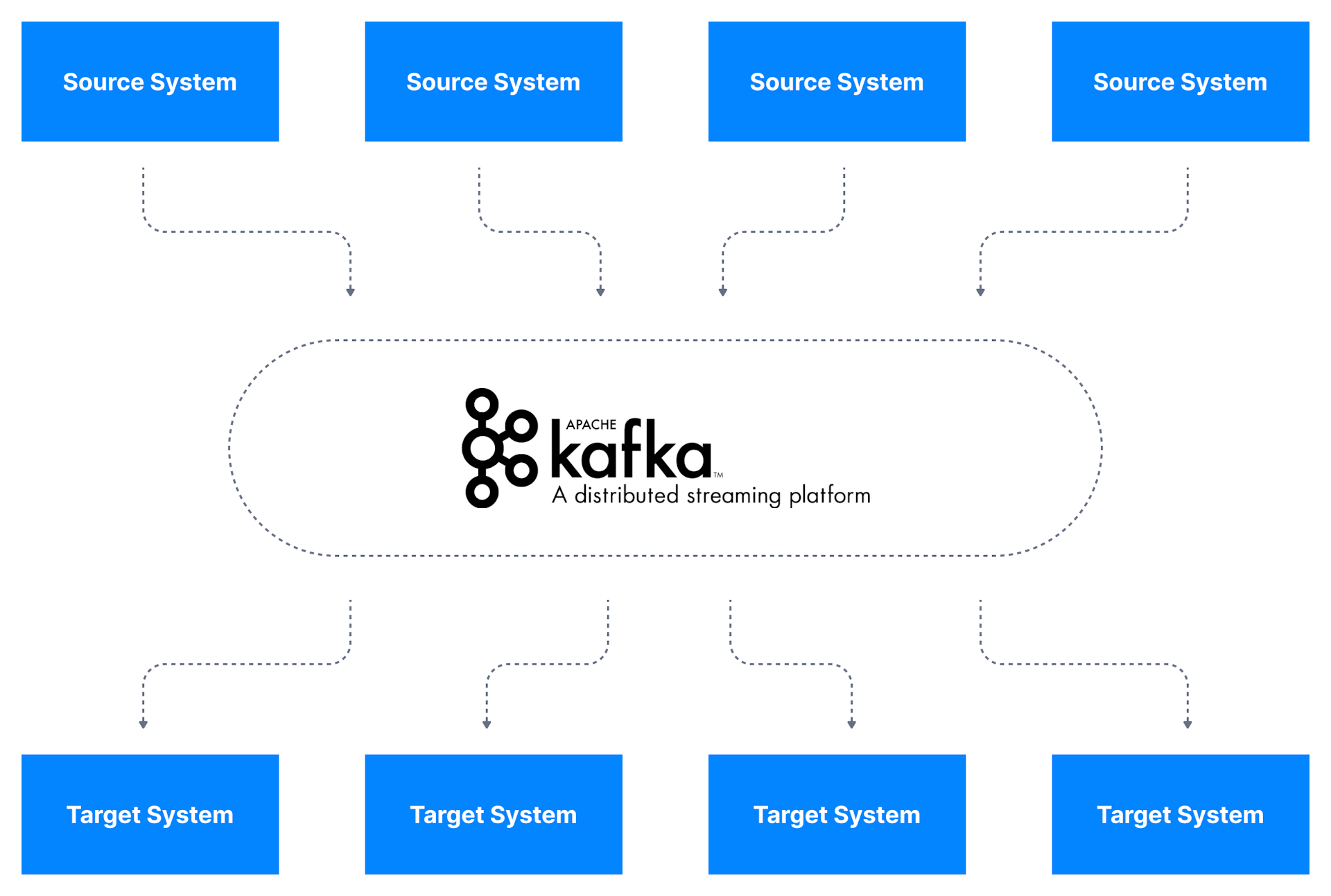
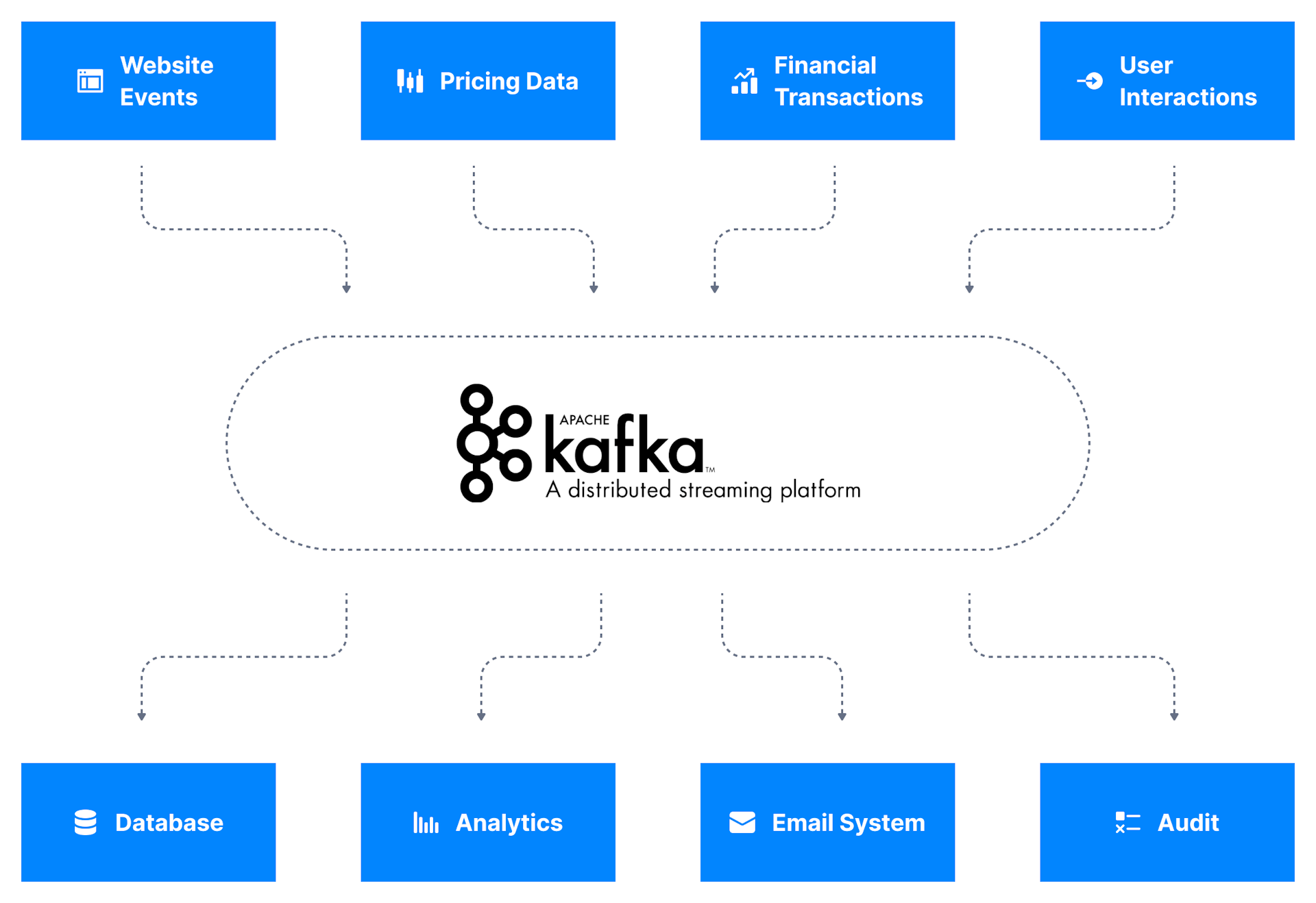
Kafka作为数据集成层,数据源将其数据发布到Kafka,目标系统从Kafka获取数据,
这将源数据流和目标系统解耦,从而实现简化的数据集成解决方案;
1.3. Data Stream
-
数据流通常被认为(typically thought of)是
潜在无限的数据序列(potentially unbound data sequence); -
数据流的数据吞吐量变化很大:有些流每秒会接收数万条记录,有些流每小时会接收一到两条记录;
-
kafka用于存储这些数据流(也称主题),然后允许系统执行流处理,
对可能无穷无尽且不断发展的数据源执行连续计算的行为; -
act of performing continual calculation on potentially
endless and constantly evolving source of data; -
一旦流被处理并存储在kafka中,它就可传输到另一个系统,如数据库;
2. Core Definition

3. Eco
3.1. Kafka Stream
-
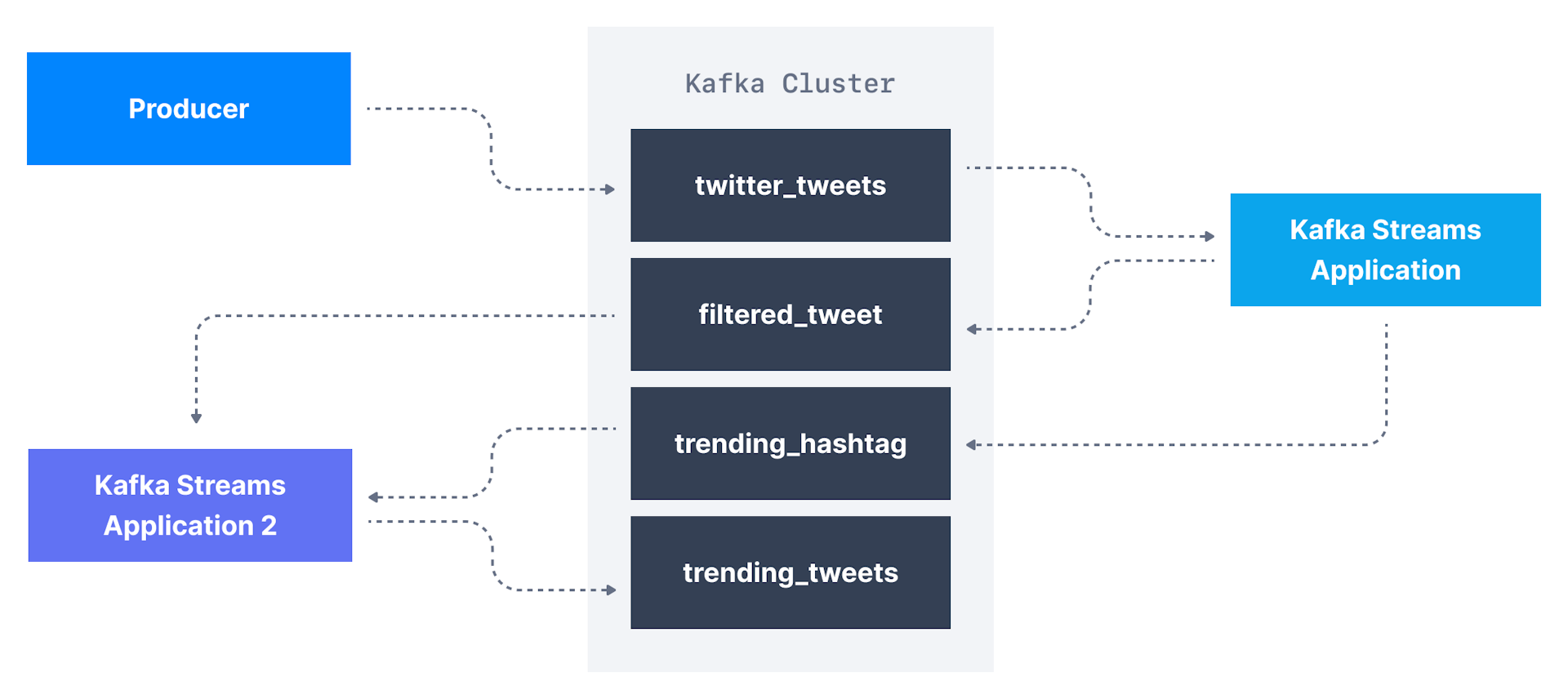
将外部系统的数据生成到Kafka中,可使用Kafka Stream流处理,
对流数据存储来提供实时分析; -
如微信过滤点赞数超过100的信息,计算每一分钟每个主题签收到的信息数量,
将两者结合,即可实现热门主题(topic)和标签(hashtag); -
kafka可执行主题级转换(topic-level transformation),
可使用适用于此用例的流库,而不是编写复杂的生产者和消费者代码; -
同类流处理框架如:kafka stream,spark,flink;

3.3. Schema Registry
-
schema registry有助于在kafka中注册数据模式(register data schema),
并确保生产者和消费者在演变(evolving)过程中相互兼容(compatible); -
schema registry支持json,protobuf,avro模式的数据格式;
-
data schema为我们的数据定义预期字段,字段名称,和值类型;
expect field,field name,field value type; -
若每schema registry,当data schema发生更改时,
生产者和消费者面临奔溃风险(breaking risk)