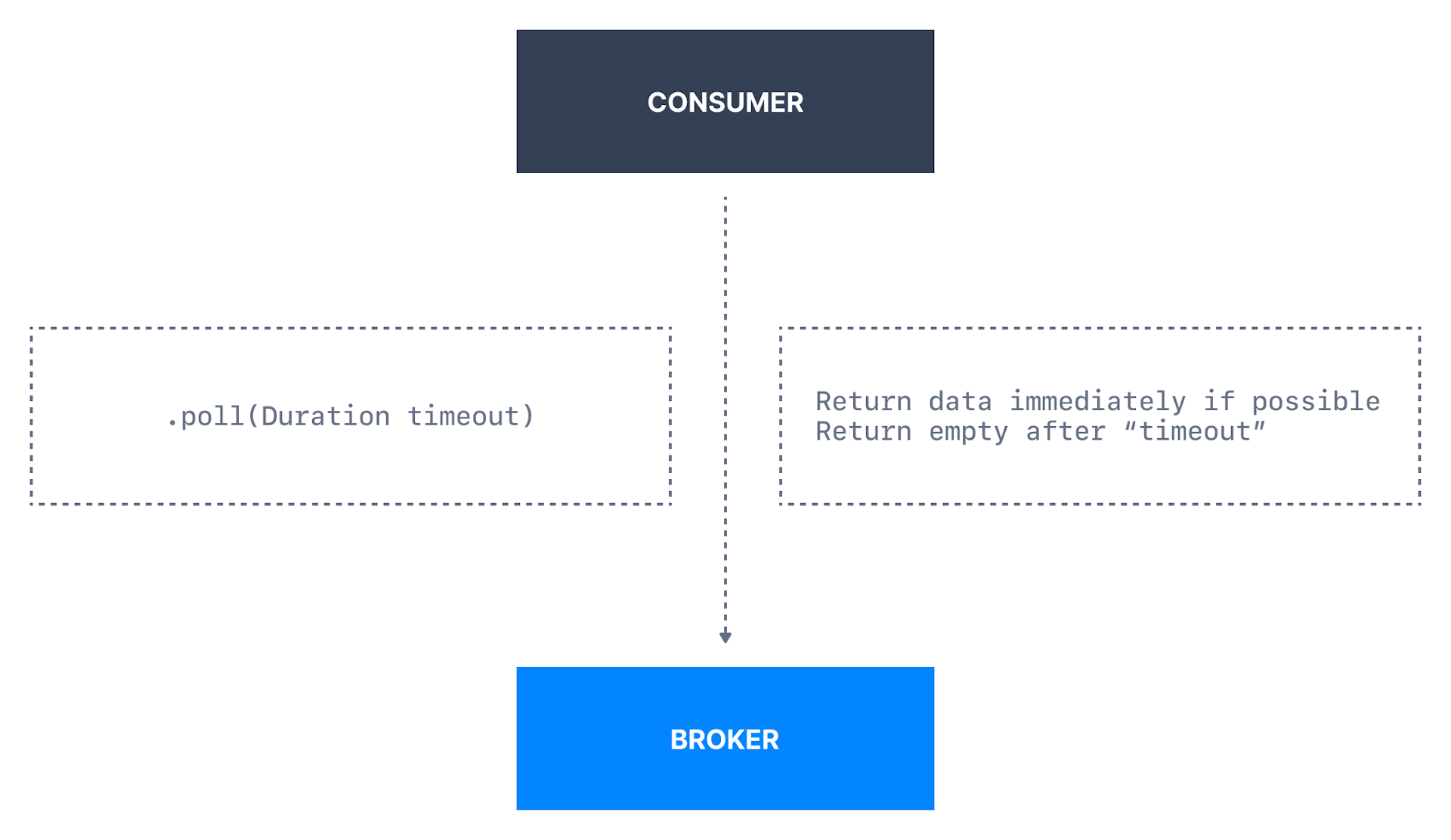
1. Consumer Poll Behavior
-
消费者poll broker以接收批量数据,一旦消费者订阅(subscribe)主题,
poll loop将处理(handle)协调(coordination)、 -
分区重新平衡(partition rebalance)、心跳(heartbeat)和
数据获取(fetching)的所有细节,干净的Api,只需从分配的分区返回可用数据; -
Internal Code Optimization 内部代码优化:
-
若消费者成功从Kafka中提取数据,它将提前开始发送下一个提取请求,当消费者
正在处理当前一批数据时,将不得不在next poll() call上等待下一个数据;
-
Polling允许消费者控制:
** A:从日志中想要消费的位置;B:想以多快的速度消费;-
C:能回放事件,ability to replay event;
-
1.1. Poll and Heartbeat
-
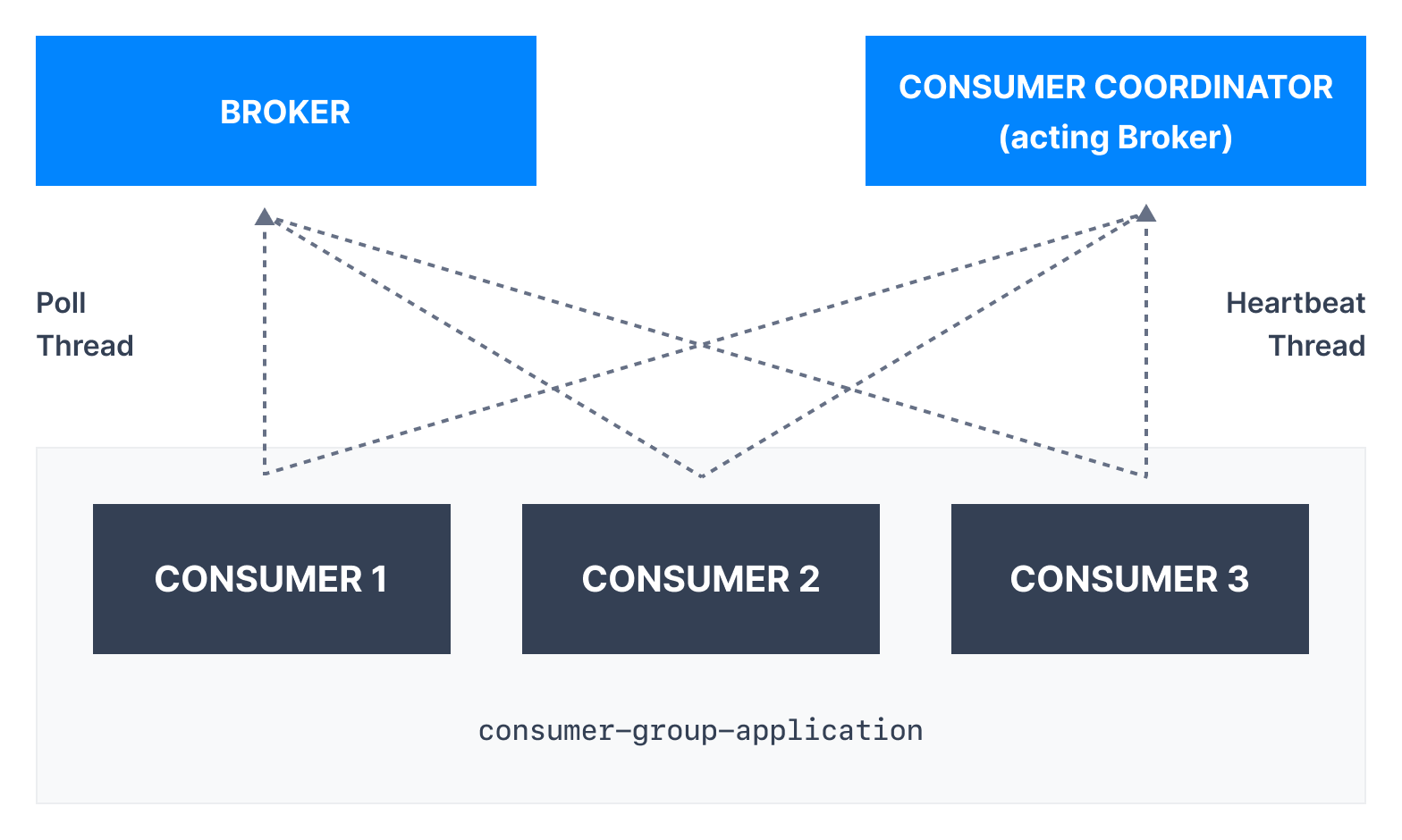
Internal Poll Thread and Heartbeat Thread
-
消费者在消费者组中维护成员和分配给他们的分区ownership
的方式是将心跳发送给指定为组协调器的broker; -
consumer maintain membership in consumer group and
ownership of partition assign to them by sending
heartbeat to broker designate as group coordinator; -
consumer poll broker for message,此两个活动在如下独立使用消费者线程上执行;
1.2. Consumer Heartbeat Thread
-
Heartbeat有助于确定消费者Liveliness;
-
只要消费者以规则的间隔发送heartbeat(heartbeat.interval.ms),
它就被认为是活动的assumed to alive,且正在处理来自其分区的消息; -
若消费者停止发送heartbeat的时间足够长(session.timeout.ms),
其会话将超时,组协调器将认为它已停止并触发重新平衡; -
session will timeout and group coordinator
will consider it dead and trigger rebalance; -
消费者心跳线程定期向消费者协调器发送心跳消息,此行为由
heartbeat.interval.ms和session.timeout.ms控制; -
consumer heartbeat thread send heartbeat
message to consumer coordinator periodically;
|
-
此两属性通常一起修改,heartbeat.interval.ms必须低于
session.timeout.ms,且通常设置为不超过超时值的1/3; -
默认值适合常规用例,故在没适当测试场景下,不应调优;
-
此机制用于检测消费者应用停机或网络故障;
1.3. Consumer Poll Thread
-
消费者使用poll()定期poll broker,若两个poll()调用之间的
间隔超过max.poll.interval.ms时间,则消费者将与组断开连接; -
max.poll.interval.ms:默认5分钟,使用消费者组管理时调用poll()
之间的最大延迟(delay),这为消费者在获取更多记录之前可空闲的时间设置上限; -
若在该超时到期之前未调用poll(),则认为消费者失败,且组将重新平衡,
以将分区重新分配给另一个成员,此设置与处理数据可能需要时间的框架(如Spark)特别相关; -
此机制用于检测detect "stuck"(aka "livelock")的消费者的数据处理问题;
-
max.poll.records:默认500,控制对poll()的单个调用将返回的最大记录数,
有助于控制应用在处理循环(processing loop)中接受的数据量; -
较低的max.poll.records可确保在达到
max.poll.interval.ms延迟(delay)前调用next.poll()
2. Consumer Fetch Behavior
-
调用poll()后,消费者将从分区中获取数据,然后消费者在主线程中处理数据,
且消费者继续优化pre-fetching下一批数据pipeline
以更快的流水线传输数据并减少处理延迟latency; -
从消费者到broker的获取请求可通过以下配置控制:
2.1. fetch.min.bytes
-
允许消费者指定在获取记录时希望从broker接收的最小数据量,默认为1;
-
若broker从消费者接收到对记录的请求,但新记录的字节数少于fetch.min.bytes,
则broker将等待更多消息可用,然后再将记录发送回消费者,基于fetch.max.wait.ms设置; -
这减少消费者和broker的负载(broker),因它们必须处理更少的来回消息
(back-and-forth message),并优化为最小的获取大小;
2.2. fetch.max.wait.ms
-
若没足够的数据立即满足fetch.min.bytes给出的要求,
则broker在回答fetch请求之前将阻止的最长时间,默认500ms; -
maximum amount of time broker will block before answering
fetch request if there isn’t sufficient data to immediately
satisfy requirement given by fetch.min.bytes; -
在满足fetch.min.bytes的要求之前,在fetch向消费者返回数据之前,
将有长达500毫秒的延迟latency,如引入潜在的延迟potential delay以提高请求的效率;