3. At Least Once
-
来自源系统的每个事件都将到达其目标,但有时重试会导致重复,偏移是在消息处理后提交,
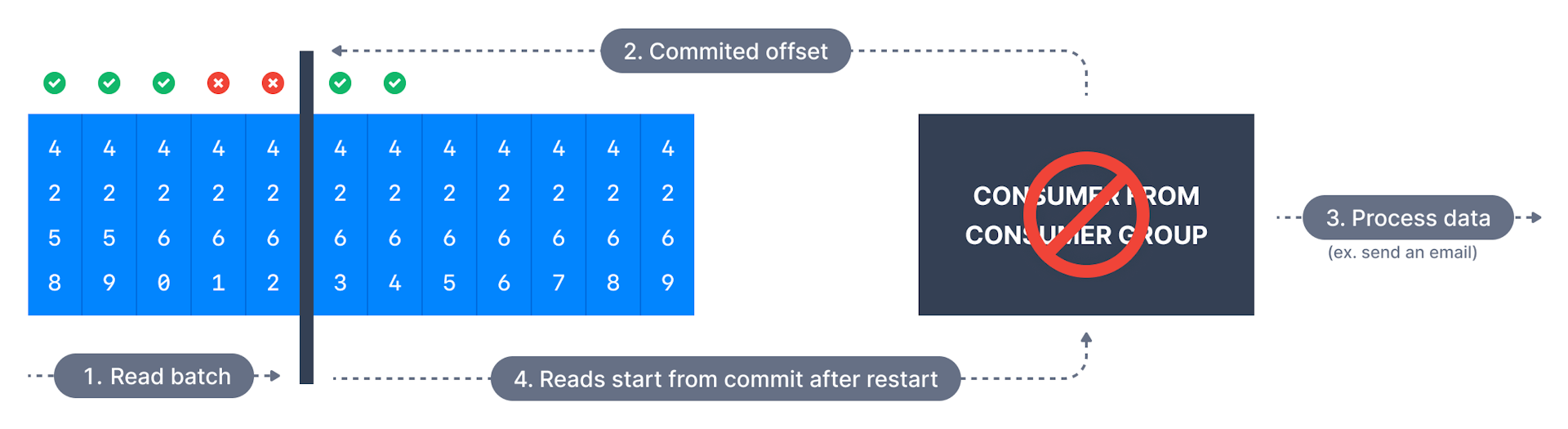
若处理出错,将再次读取消息,可能导致重复处理消息,适于无法承受任何数据丢失的消费者; -
通常是是首选策略,确保处理是幂等的(idempotent,即再次处理消息不会影响系统);
4. Exactly Once
-
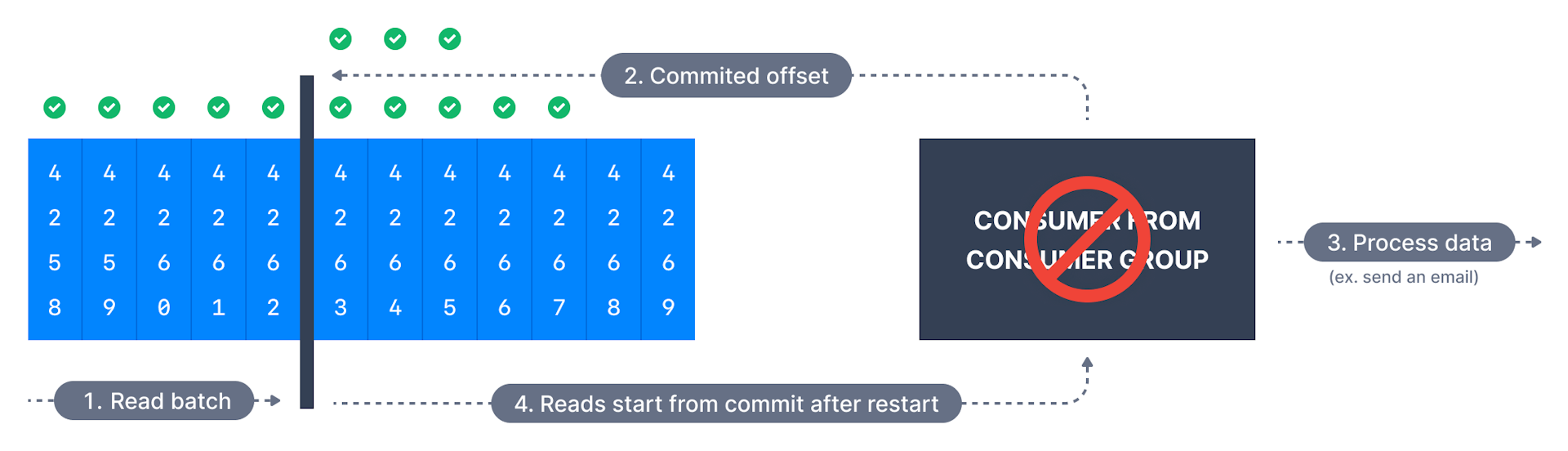
有些应用不仅需at-least-once语义,即没数据丢失,还需exactly-once语义,
每条消息只传递一次,某些情况下若Kafka和消费者应用合作cooperate,使语义精确一次; -
这只能通过使用事务Api实现主题到主题的工作流topic to topic workflow,
kafka stream简化api的使用,设置:processing.guarantee=exactly.once -
对主题到外部系统的工作流topic to external system workflow,
要有效地实现精确一次effectively achieve exactly once,
必须使用幂等消费者must use idempotent consumer;
5. Summary
| Entry | Memo |
|---|---|
At Most Once |
一旦收到消息,就提交偏移,若处理出错,消息将丢失,不会再次读取 |
At Least Once |
在处理消息后提交偏移量,若处理出错,将再次读取消息, |
Exactly Once |
可使用高级Stream Api或低级Transactions |
-
对大多应用,应使用"At Least Once"处理,并确保转换/处理
transformation/processing是幂等idempotent;
6. Automatic Offset
-
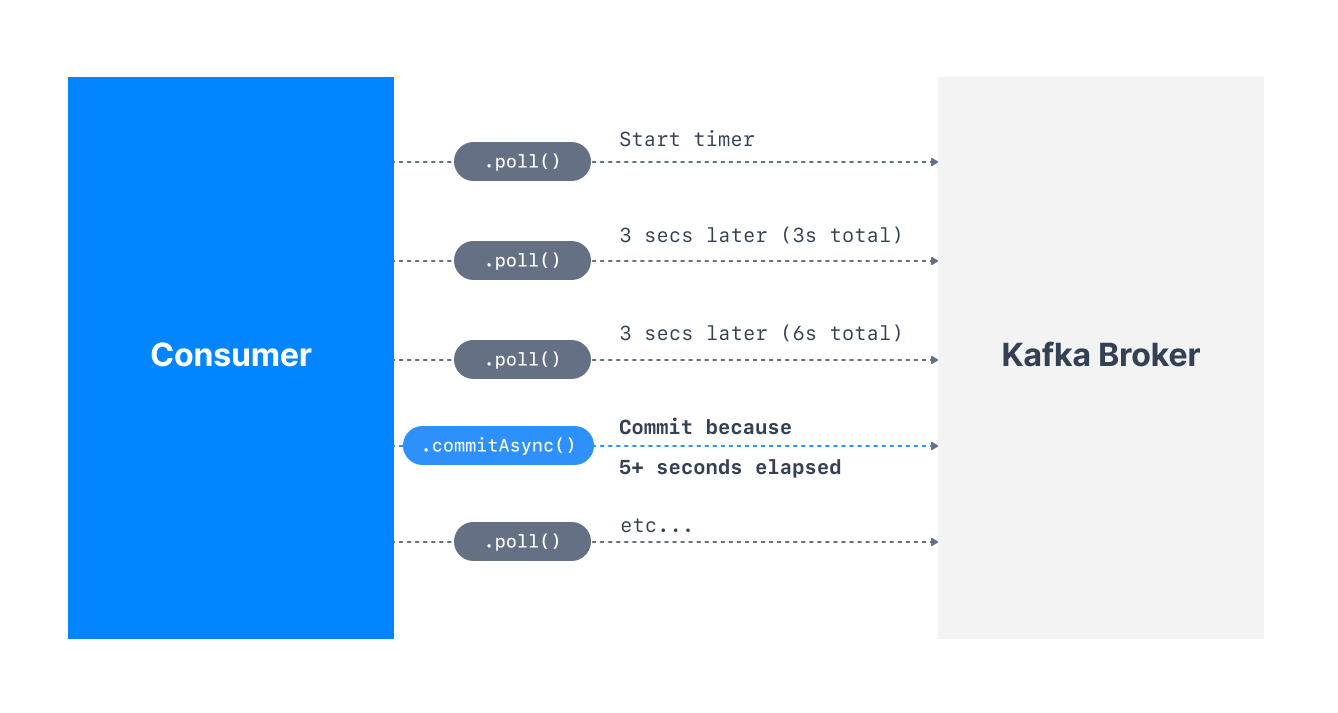
Consumer Java Api会定期自动提交偏移量,以便启用at-least once读取场景;
-
https://www.conduktor.io/kafka/kafka-consumer-groups-and-consumer-offsets
-
默认:属性enable.auto.commit=true,故偏移量
以配置auto.commit.interval.ms控制的频率自动提交; -
提交偏移量的过程发生在以下情况:
-
call poll();
-
两次调用poll()之间的时间大于设置auto.commit.interval.ms(默认5s);
-
-
即要处于"at-least-once"处理用例(最理想的用例)中,需确保
在执行另一个poll()调用之前成功处理消费者代码中的所有消息; -
若不是此种情况,那偏移量可能会在消息实际处理之前提交,
从而导致"at-most once"的处理模式,可能导致消息
跳过skipping,这是不可取的undesirable; -
在此罕见(rare)情况下,必须禁用enable.auto.commit,且很可能禁用对单独线程
的大多数处理,然后不时手动调用具有正确偏移量的commitSync()或commitAsync();