1. Train Model
-
模型使用随机参数(random parameter)计算进行预测,
即猜测(随机)basically guessing (randomly); -
为解决此问题,可更新内部参数(internal parameter),
也将参数称为模式pattern,使用nn.Parameter()和torch.randn()
随机设置的权重weight和偏差值(bias value),使其更好的表示数据; -
可对此硬编码(因我们知道默认值,weight=0.7和bias=0.3),
很多时候不知道模型的理想参数是多少,相反,编写代码找出最佳值很有趣; -
在PyTorch中创建损失函数loss function和优化器optimizer,
为使模型自行更新其参数,需在recipe中添加更多内容;
1.1. Loss Function Optimizer
| Function | Do What | Where Live | Common Value |
|---|---|---|---|
Loss Function |
|
PyTorch在torch.nn中有很多(plenty of)内置的损失函数 |
|
Optimizer |
|
在torch.optim中查找各种优化函数的实现 |
|
|
# create loss function,MAE loss is same as L1Loss
loss_fn = nn.L1Loss()
# create optimizer
# parameter of target model to optimize
# learning rate:how much optimizer should change parameter at each step,
# higher=more (less stable),lower=less (might take long time))
optimizer = torch.optim.SGD(params=model_0.parameters(),lr=0.01)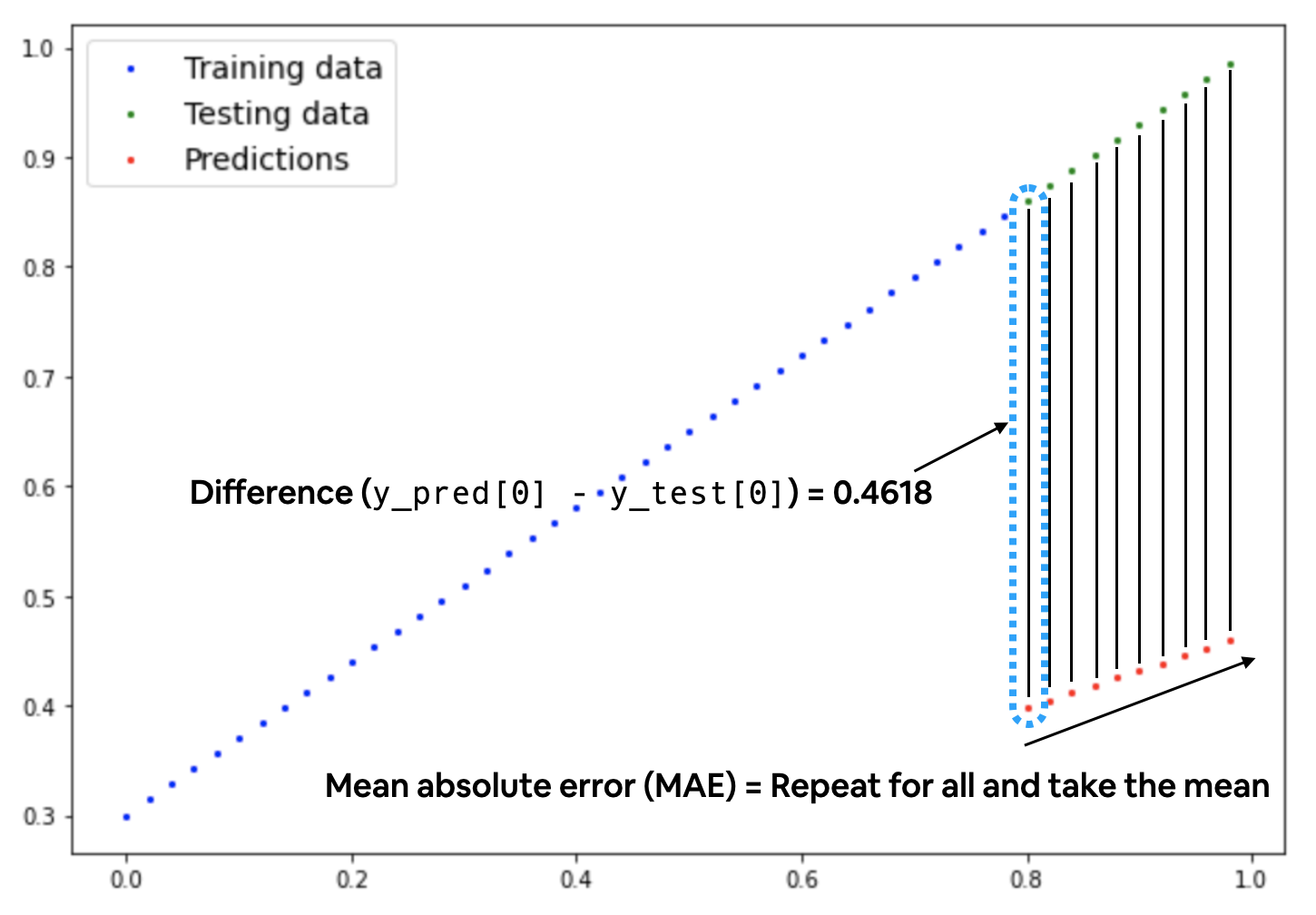
1.2. Optimization Loop
* 训练循环training loop涉及模型遍历训练数据并学习特征和标签之间的关系;
-
测试循环testing loop涉及遍历测试数据并评估模型在训练数据上
学习的模式有多好(模型在训练期间永远不会看到测试数据); -
循环loop:希望模型查看(循环遍历loop through)每个数据集中的每个样本;
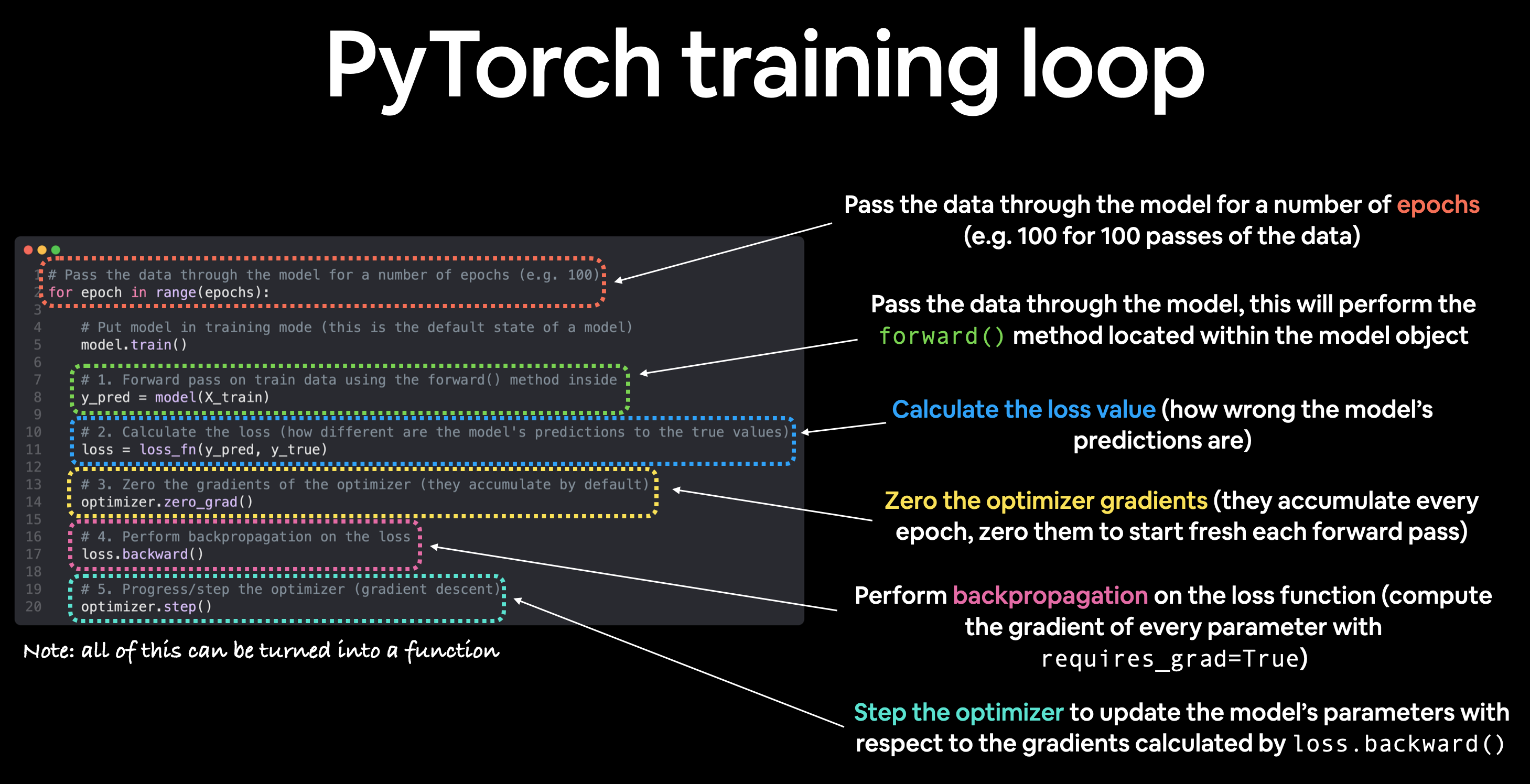
1.3. Training Loop
| Number | Step Name | Code | Do What |
|---|---|---|---|
1 |
Forward Pass |
model(x_train) |
该模型会遍历所有训练数据一次,并执行其forward()函数计算 |
2 |
Calculate Loss |
loss=loss_fn(y_pred,y_train) |
将模型的输出(预测)与ground truth比较,并评估以查看其错误程度 |
3 |
Zero Gradient |
optimizer.zero_grad() |
优化器的梯度gradient设置为零(默认是累积的 |
4 |
Perform Backpropagation on Loss |
loss.backward() |
计算每个要更新的模型参数(每个参数的require_grad=True)的 |
5 |
update optimizer(gradient descent) |
optimizer.step() |
用require_grad=True来根据损失梯度更新参数,以改进它们 |
|
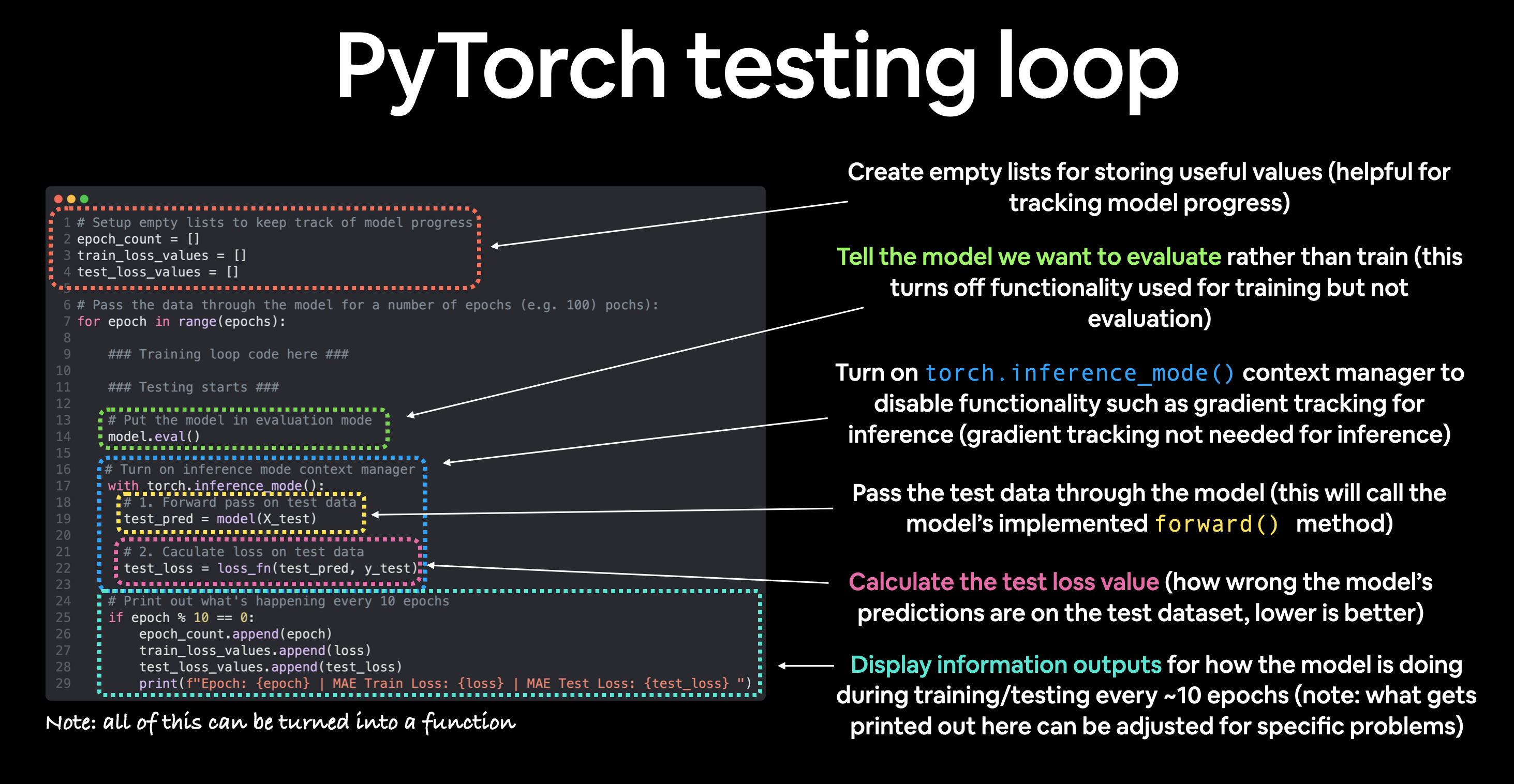
1.4. Testing Loop
| Number | Step Name | Code | Do What |
|---|---|---|---|
1 |
Forward Pass |
model(x_test) |
该模型遍历所有训练数据一次,执行其forward()函数计算 |
2 |
Calculate Loss |
loss=loss_fn(y_pred,y_test) |
将模型的输出(预测)与ground truth比较并评估,以了解它们的错误程度 |
3 |
Calulate Evaluation Metric(optional) |
Custom Function |
除alongisde损失值,可能还需计算其他评估指标,如测试集的准确性accuracy |
|
-
我们把以上所有问题放一起,训练模型100个epoch(通过数据向前,
forward pass through data),将每10个epoch对其评估;
torch.manual_seed(42)
# set epoch number(how many times model will pass over training data)
# 设置时期的数量(模型将通过训练数据的次数)
epoch = 100
# create empty loss list to track value
train_loss_value = []
test_loss_value = []
epoch_count = []
for e in range(epoch):
### Training
# put model in training mode (model default state)
model_0.train()
# 1:Forward Pass on train data via forward() method inside
y_pred = model_0(X_train)
# print(y_pred)
# 2:Calculate Loss (how different model prediction to ground truth)
loss = loss_fn(y_pred,y_train)
# 3:Zero Grad of optimizer
optimizer.zero_grad()
# 4:Loss Backward
loss.backward()
# 5:Progress optimizer
optimizer.step()
### Testing
# put model in evaluation mode
model_0.eval()
with torch.inference_mode():
# 1:Forward Pass on test data
test_pred = model_0(X_test)
# 2:Caculate Loss on test data,prediction come in torch.float datatype,
# so comparison need to be done with tensor of the same type
test_loss = loss_fn(test_pred, y_test.type(torch.float))
# Print Out What Happening
if e % 10 == 0:
epoch_count.append(e)
train_loss_value.append(loss.detach().numpy())
test_loss_value.append(test_loss.detach().numpy())
print(f"Epoch: {e} | MAE Train Loss: {loss} | MAE Test Loss: {test_loss} ")
# Plot Loss Curve
plt.plot(epoch_count, train_loss_value, label="Train Loss")
plt.plot(epoch_count, test_loss_value, label="Test Loss")
plt.title("Training and Testing Loss Curve")
plt.ylabel("Loss")
plt.xlabel("Epoch")
plt.legend();
plt.savefig("TrainingTestingLossCurve.svg")Epoch: 0 | MAE Train Loss: 0.31288138031959534 | MAE Test Loss: 0.48106518387794495
Epoch: 10 | MAE Train Loss: 0.1976713240146637 | MAE Test Loss: 0.3463551998138428
Epoch: 20 | MAE Train Loss: 0.08908725529909134 | MAE Test Loss: 0.21729660034179688
Epoch: 30 | MAE Train Loss: 0.053148526698350906 | MAE Test Loss: 0.14464017748832703
Epoch: 40 | MAE Train Loss: 0.04543796554207802 | MAE Test Loss: 0.11360953003168106
Epoch: 50 | MAE Train Loss: 0.04167863354086876 | MAE Test Loss: 0.09919948130846024
Epoch: 60 | MAE Train Loss: 0.03818932920694351 | MAE Test Loss: 0.08886633068323135
Epoch: 70 | MAE Train Loss: 0.03476089984178543 | MAE Test Loss: 0.0805937647819519
Epoch: 80 | MAE Train Loss: 0.03132382780313492 | MAE Test Loss: 0.07232122868299484
Epoch: 90 | MAE Train Loss: 0.02788739837706089 | MAE Test Loss: 0.06473556160926819
|
# find model learned parameter
print("model learned following value for weight and bias:")
print(model_0.state_dict())
print("\noriginal value for weight and bias:")
print(f"weight: {weight}, bias: {bias}")model learned following value for weight and bias:
OrderedDict({'weight': tensor([0.5784]), 'bias': tensor([0.3513])})
original value for weight and bias:
weight: 0.7, bias: 0.3-
模型非常接近于计算权重和偏差的确切原始值,若训练更长时间,可能会变得更接近;
-
尝试将上面的epoch修改为200,模型的损失曲线,权重和偏差值会发生啥?